
编写高效 CSS 选择器
作者:大漠 日期:2021-09-25 点击:616
特别声明:如果您喜欢小站的内容,可以点击申请会员进行全站阅读。如果您对付费阅读有任何建议或想法,欢迎发送邮件至: airenliao@gmail.com!或添加QQ:874472854(^_^)
早在十多年前,在社区就有很多专业人士探讨和深究过 CSS 选择器对渲染性能的影响。特别是对于今天的现代浏览器而言,他们经过了多年的变化(和优化),浏览器变得更聪明!对于 Web 开发人员,“不应该需要担心优化选择器的问题”,他对页面的渲染性能影响已经非常的小,正如 Antti Koivisto所说:
“My view is that authors should not need to worry about optimizing selectors (and from what I see, they generally don’t), that should be the job of the engine.”
即使如此,CSS的选择器的使用还是有分高效和非高效的,我们在编码的时候,还是应该尽可能的使用高效的CSS选择器,因为高效的CSS选择器对于页面的渲染是有一定帮助的,哪怕这种帮助很微小。但对于追求极致的渲染体验,这一切都是值得的,因为你要付出的并不会太多,反而得到的会较多。
如果对网站的所有领域,包括CSS都进行微小的改进,那么他们将产生更多的实质性变化;用户总是会受益的!
CSS 是如何在浏览器中工作的
在《初探 CSS 渲染引擎》都提到 CSS 的选择器的解析会涉及到 样式计算和渲染树的影响。浏览器在构建了 DOM 和 CSSOM 之后,浏览器需要将两者合并成渲染树,在这一步,浏览器需要弄清楚每个元素的计算CSS。这个样式匹配中不可或缺的就是 CSS 的选择器,只有选择器配对成功的 CSS 才会用来进行样式计算,与 DOM节点匹配,构建出 CSSOM树。在这个过程中,也有可能致使计算过的样式失效(比如动态改了DOM节点或选择器),浏览器也需要使匹配的选择器树下的扎有内容失效,从而造成样式的重新计算。在渲染性能方面,这个过程也是较为耗时的,因此,为了避免这个问题的出现,其中有一个方法就是 减少CSS选择器的复杂性。即:编写高效的CSS选择器!
在介绍如何编写高效的CSS选择器之前,我们有必要先花点时间了解 CSS在浏览器中是如何工作的?
我们知道,一个浏览器大概包括以下几个重要部分(高级组件):

浏览器的渲染引擎对网页的内容进行渲染。默认情况下,渲染引擎可以渲染 HTML、XML 和 图像(Image)。它根据请求的 URL 接收到的响应的 MIME 类型来渲染内容。例如,如果 MIME 类型是 text/html ,渲染引擎会解析 HTML 和 CSS ,并渲染内容。
渲染引擎的主要流程
渲染引擎从网络层获取文档的内容,通常是以 8kb 为单位,并对文档的内容进行以下工作。渲染是一个渐进的过程,当渲染引擎开始接收到要渲染的文档内容时,它就开始渲染!
- 内容树的构建:HTML 元素被转换为 DOM 节点,即 DOM 树
- 渲染树的构建:样式被解析(即 CSSOM 树)并添加到 DOM树中以生成渲染树(即 Render 树)
- 布局过程:渲染树的每个节点被分配一个位置
- 绘制过程:渲染树的每个节点使用 UI 后台(UI Backend)进行绘制
整个渲染过程如下图所示:
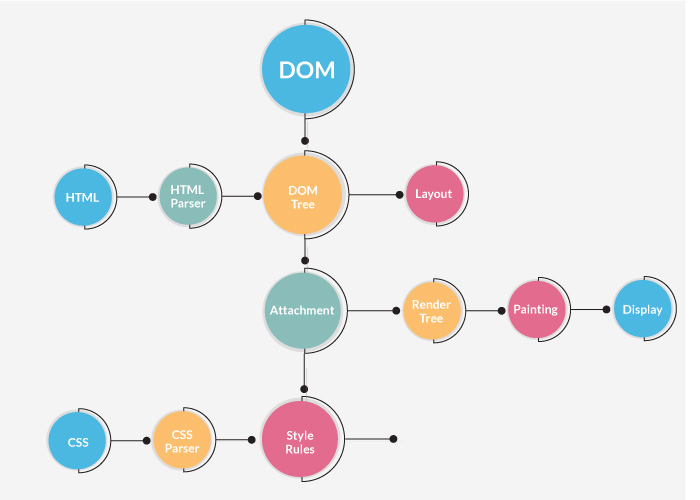
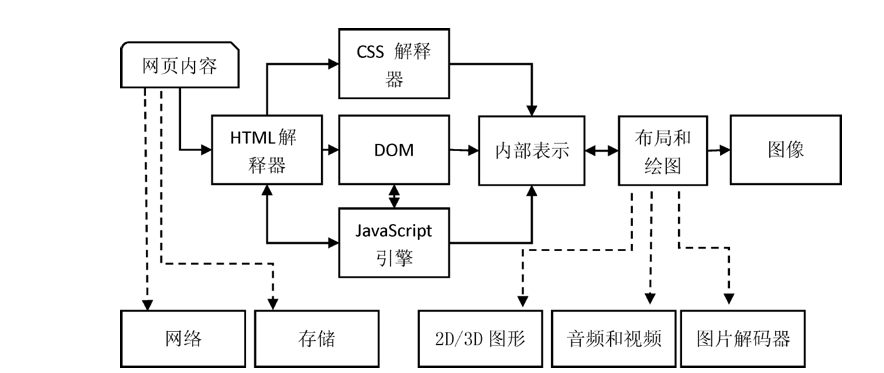
图:Webkit 内核渲染的过程
解析
解析是由渲染引擎进行的关键过程。解析是一个过程,在这个过程中,输入被分解成更小的元素,以便将输入转换为其他格式。解析过程产生了由节点树组成的文档结构。
比如表达式(2 + 3 - 1) ,解析之后如下图这样:
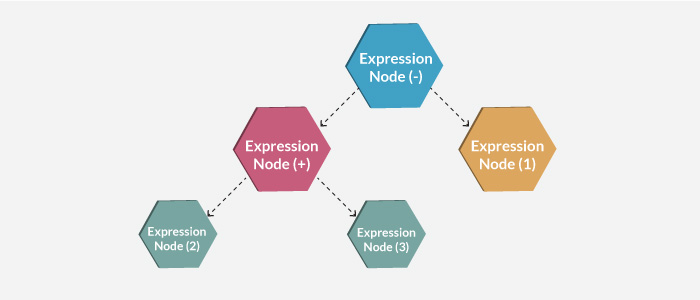
上图:数学表达式树节点
根据文档所遵循的词汇和语法规则对其进行解析。这些规则称为 无语镜语法,必须遵循代码才能被解析!
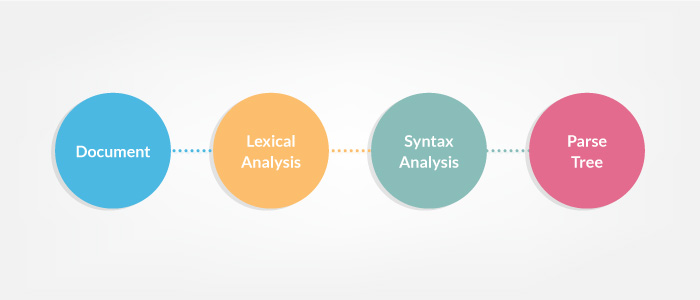
图:文件到解析树
解析由两个过程组成:
- 词法解析(Lexical Analysis Process):在词法解析过程中,代码被分解为标记,这些标记是语言词汇表中的有效元素。它有词法分析器(Lexer)或 令牌器(Tokenizer)执行。这个过程也被称为 Token 化
- 语法解析(Syntax Analysis Process):在语法分析过程中,语法规则被应用于由词法分析器(Lexer)返回的标记上
解析是一个递归过程。解析器试图将语法规则(Syntax Rules)与词法(Lexical)返回的标记相匹配。如果语法规则匹配,该标记就会被添加到解析树中,解析器会要求提供一个新的标记。如果该规则没有被匹配,那么该标记将被保存在内部,解析器将要求提供新的标记,直到找到一个与所有内部存储的标记相匹配的规则。如果规则没有被匹配,解析器会引发一个异常。这意味着按照无语境语法(上下文自由语法),该文档是无效的。
词汇和句法的表示
- 语言的词汇以正则表达式的形式表达:上下文自由语法(Context Free Grammar)是以 Backus-Naur 形式的符号(表示法)技术来定义的,它被用来描述计算机中使用的语言的语法,比如计算机编程语言、文件格式、指令集和通信协议等。
- 解析器的类型:解析器的类型主要有两种,自上而下的解析器(Top-down Parsers) 和 自下而上的解析器(Bottom-up Parsers)
- 自上而下的解析器(Top-down Parsers):该解析器检查语法的高级结构,并试图找到一个规则匹配
- 自下而上的解析器(Bottom-up Parsers):该解析器从输入开始,逐渐将其转化为语法规则,从低级规则开始,直到满足高级规则
还是拿 (2 + 3 -1) 表达式为例,看看这两种类型的解析器如何解析。
自上而下的解析器将从高级别(high-level)的规则开始:它将 2 + 3 标识为表达式。然后它将 2 + 3 - 1 标识为另一个表达式(识别表达式的过程是不断发展的,与其他规则相匹配,但起点是最高级别的规则)。
自下而上的解析器将扫描输入,直到有匹配的规则为止。然后,它将用该规则替换匹配的输入。这将一直持续到输入的结束。部分匹配的表达式被放在解析器的堆栈中。这种自下而上的解析器被称为 Shift-reduce解析器,因为输入被右移(想象一下,一个指针(光标指示器)首先指向输入的起点,然后随着输入向右移动),并逐渐还原为语法规则。

HTML 解析器
HTML解析器(HTML Parser)将 HTML 标记转换为解析树。 W3C HTML5 语法规范中定义了 HTML 的语法。HTML 不容易被解析器所需要的无语境语法所定义。有一种定义 HTML 的正确格式,即 DTD(Document Type Definition),但它不是一种无语境语法(Context Free Grammar)。由于 HTML 的语法不是无语境(也称无上下文)的,所以传统的解析器不能轻易地对其进行解析。 HTML 不能被 XML 解析器所解析。
HTML 符合数据类型定义格式,该格式用于定义 SGML系列的语言。该格式包含所有允许的元素、它们的属性和层次结构的定义。 HTML DTD 并不构成无语境语法。
DTD有一些变体。严格模式(Strict Mode)完全符合规范,但其他模式包含对浏览器过去使用的标记的支持。其目的是向后兼容较旧的内容。然而, HTML5 并非基于 SGML 的,因此不需要对 DTD 的引用。
文档对象模型(DOM)是一个平台和语言无关的接口,它允许程序和脚本动态访问和更新文档的内容、结构和样式。解析树(Parse Tree)是一个由 DOM 元素和属性节点组成的树状结构。
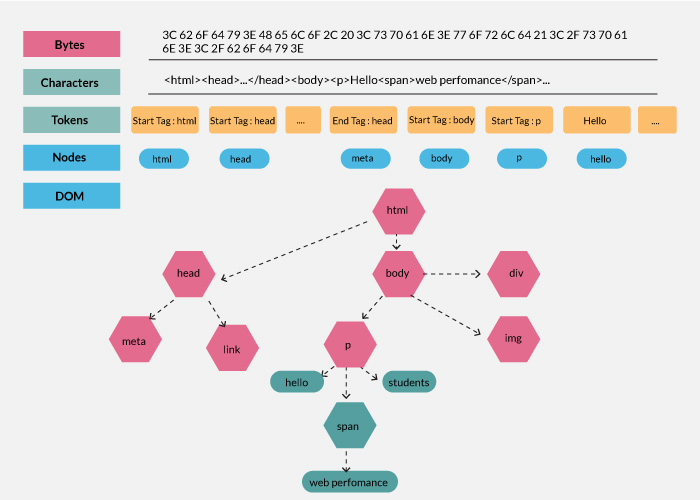
图:DOM 树(DOM Tree)
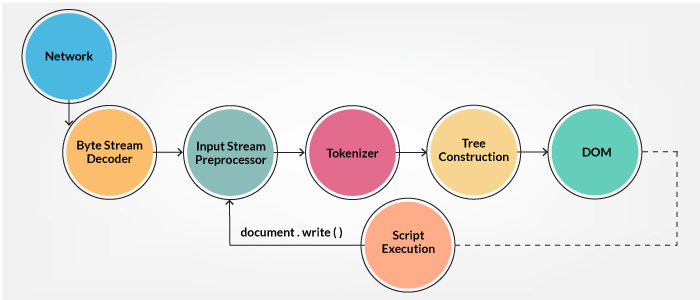
图:HTML 解析过程
给定一个编码,输入流中的字节必须转换为 Unicode 字符,以便标记(Token),这些过程在字节流解码器(Byte Stream Decoder)和输入流预处理器(Input Stream Preprocessor)中进行。标记化(Tokenizer)是语法解析(Lexical Analysis),将输入解析为标记。在 HTML 标记中,有开始标记(<)、结束标记(>)、属性名称(Attribute Name)和 属性值(Attribute Value)。标记化(Tokenizer)识别出标记(Token),将其交给树形构造器(Tree Construction),并使用下一个字符来识别下一个标记,以此类推,直到输入的结束。
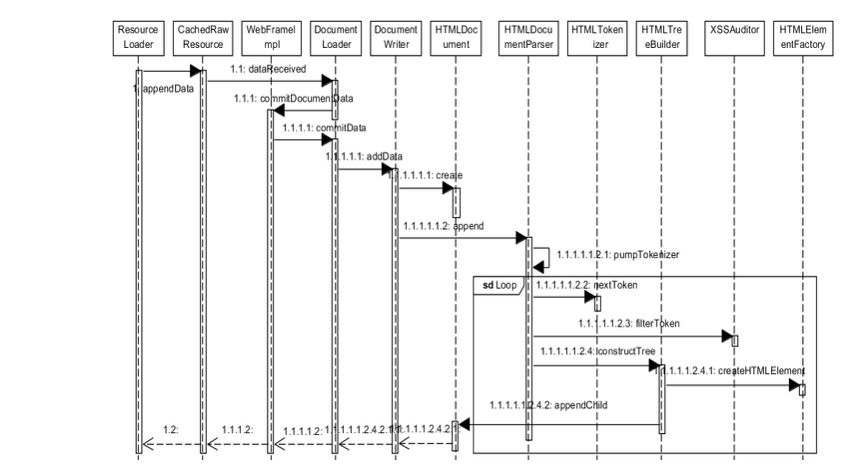
图:构建 DOM 树的的过程(Webkit内核)
CSS 解析器
CSS 字节被转换为字符,然后是标记,然后是节点,最后它们被链接到一个被称为 CSS 对象模型(CSSOM) 的树状结构。
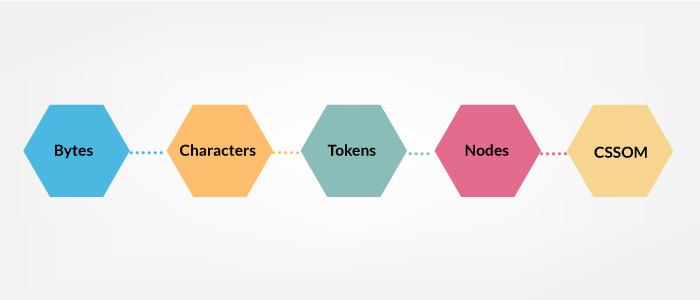
图:CSS 解析过程
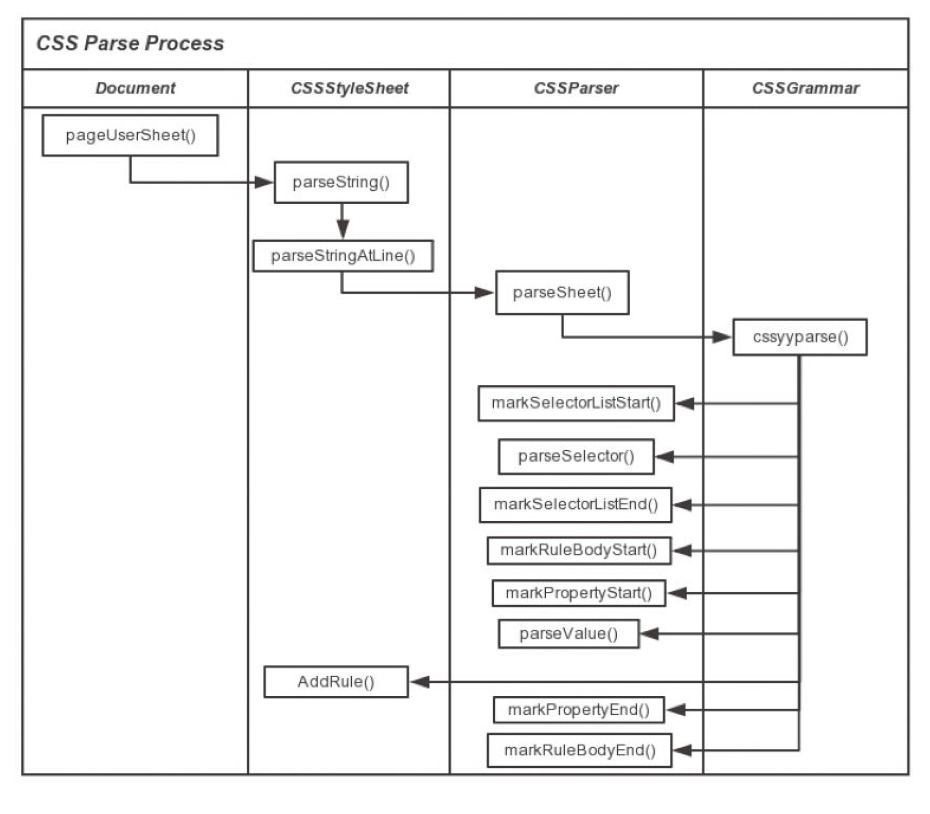
图:CSS 解析过程(Webkit内核)
当计算页面上任何对象的最终样式集时,浏览器从适用于该节点的最一般的规则开始(例如,如果它是一个 body 元素的子元素,那么所有的 body 样式都适用),然后通过应用更具体的规则递归地完善计算出的样式;也就是说,规则是“层叠向下”的。
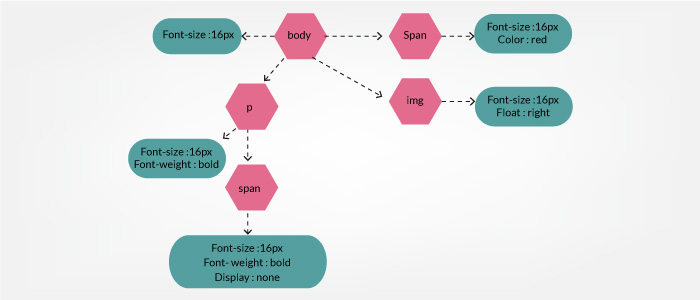
图:CSSOM 树(CSSOM Tree)
W3C CSS 2.2 Grammar 文档中对 CSS 语法进行了定义!
Webkit 使用 Flex(Flex Lexical Analyzer Generator) 来生成扫描器(Scanners)或词汇器(Lexers),使用 Bison 来生成解析器(Parser)。这些生成器使用 CSS 语法文件来生成 Lexer 和 Parser。 Bison 生成的是自下而上的 Shift-Reduce解析器。 Firefox 使用手动编写的自上而下的解析器。在这两种情况下,每个 CSS 文件都被解析为一个 CSSStyleSheet 对象,每个对象都包含 CSS 规则。CSS 规则(cssRules)对象包含选择器和声明对象以及其他对应于CSS语法的对象。接下来会进行 CSSRule 的匹配过程,去找到能够和 CSSRule Selector部分匹配的 THML 元素。
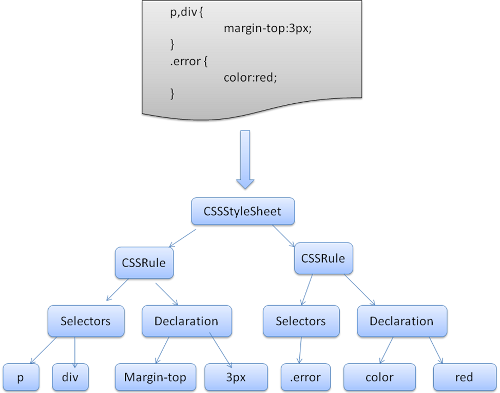
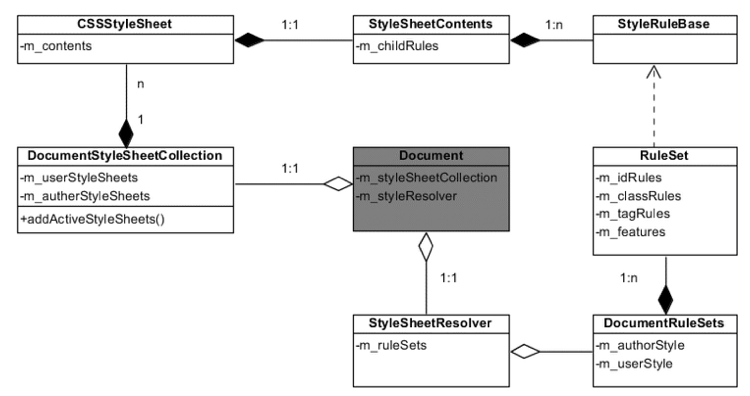
图:CSS 主要类与关系
Document 里包含了一个 DocumentStyleSheetCollection 类和一个 StyleSheetResolver 类, DocumentStyleSheetCollection 包含了所有的 StyleSheet,StyleSheet里包含了CSS 的 href,类型,内容等信息。
StyleSheetResolver 负责组织用来为 DOM 里的节点匹配的规则,里面包含了一个 DocumentRuleSets 的类,用来表示多个 RuleSet。
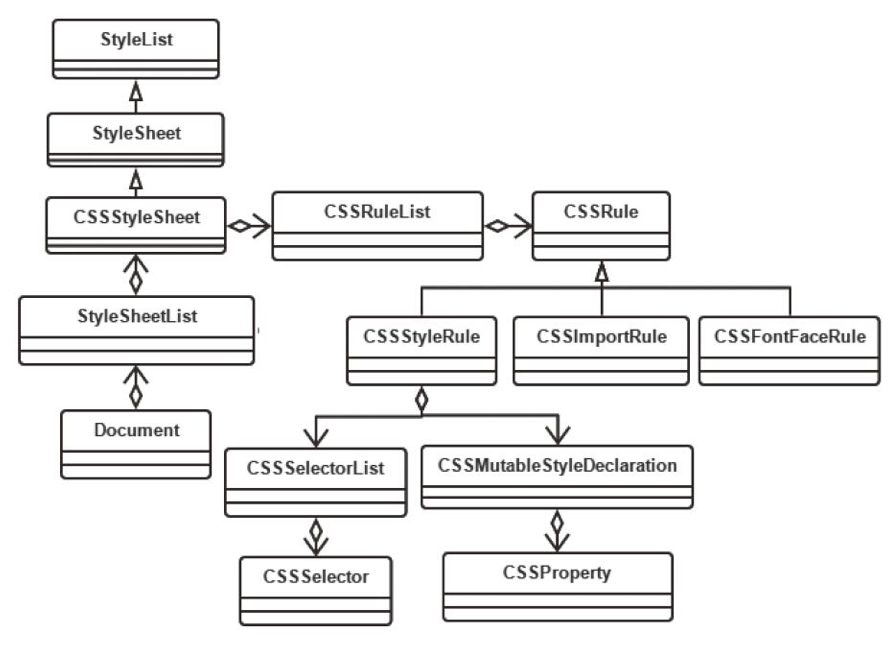
图:CSS 文档结构的类
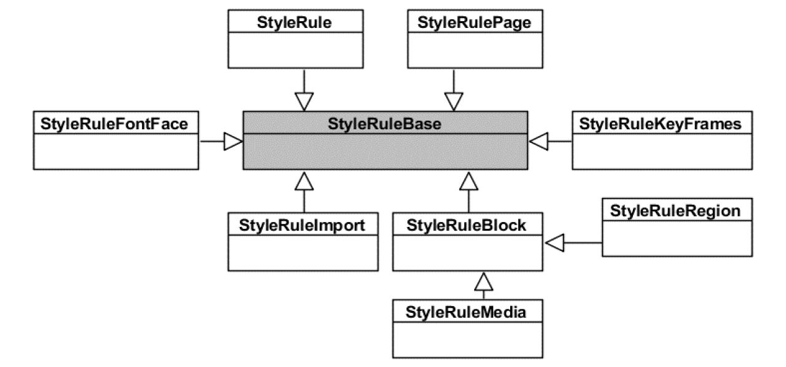
图:StyleRuleBase 相关继承关系
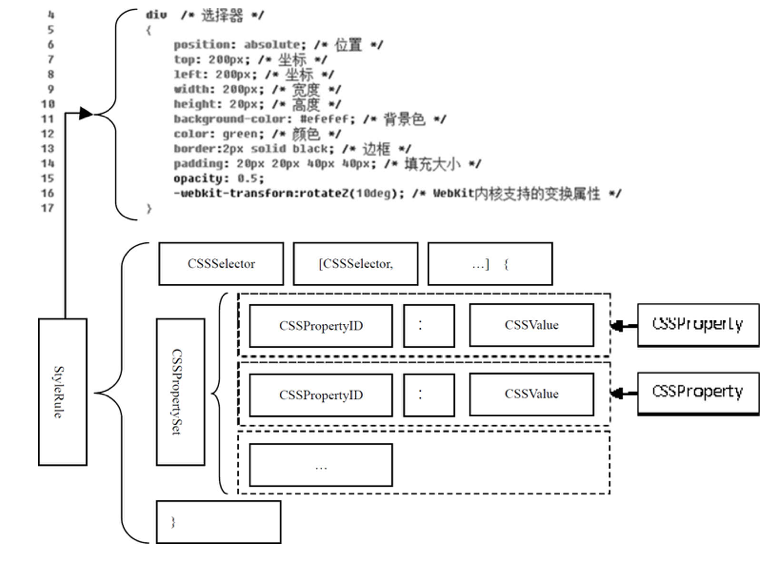
图:StyleRule 类的结构
我们可以使用 document.styleSheets 把页面 CSS 相关信息打印出来:
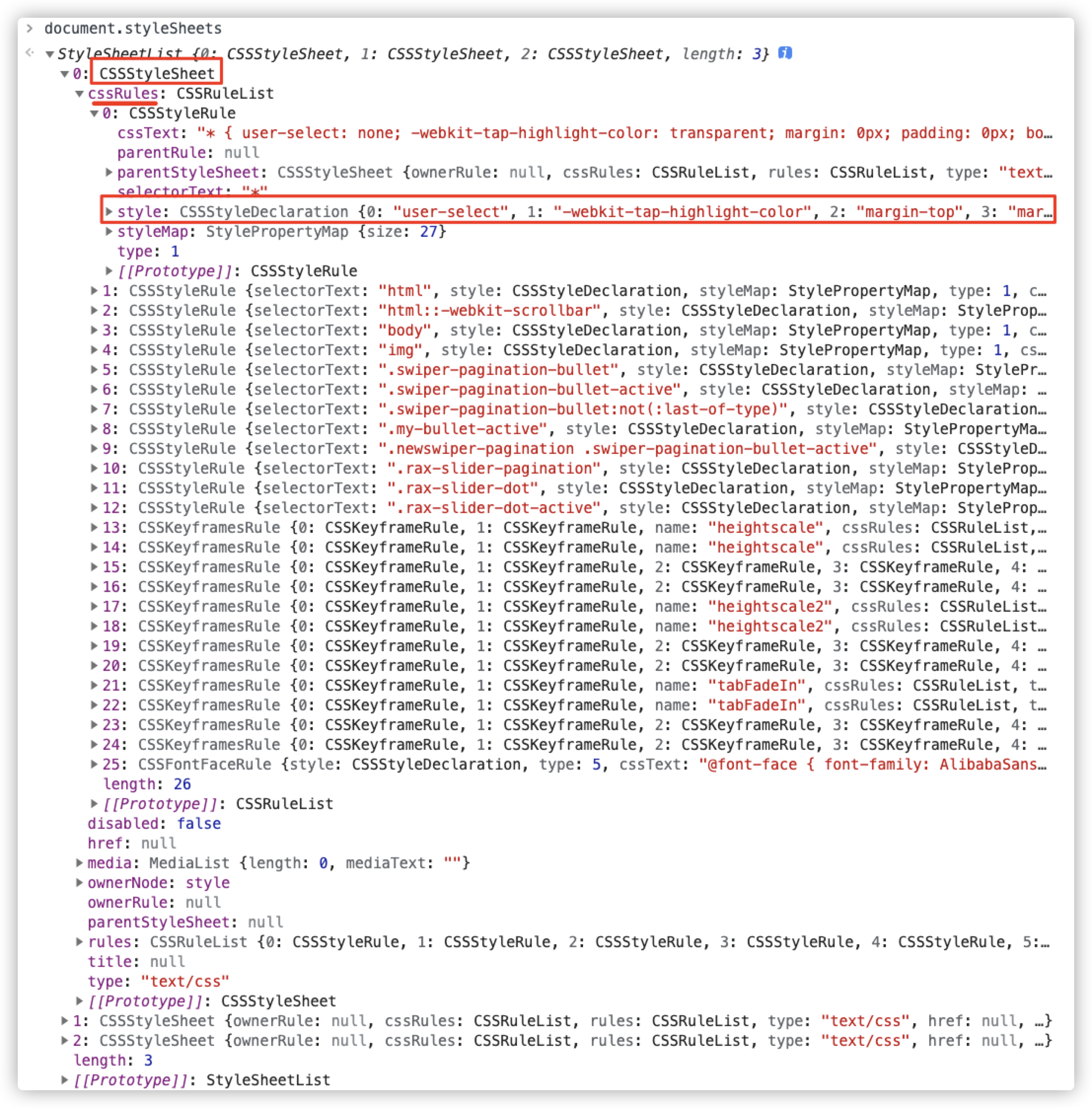
通过 styleSheets ,我们可以看到以下几个信息:
- 页面 CSS 结构解析之后生成 CSSOM 树中,多少个
style标签,在StyleSheetList对象中应用几条规则 - 按照先后顺序,
StyleSheetList先插入的是开发样式、其次是浏览器用户样式,最后面的规则是浏览器默认样式,优先级最低 - 每一条规则都有一个
disabled属性,控制该规则何时生效 - CSS样式解析生成规则之后存储在
cssText对象上 - 在单条
style规则中,规则由cssText、style、selectorText、parentStyleSheet等对象组成,供开发者访问操作 - 返回的是一个
CSSStyleDeclaration集合,和上面规则中的style对象是同一种类型,里面存储了所有CSS属性的值,没有添加样式的都为空(null) - 每个元素上都有样式(
style)接口 - 通过 JavaScript 脚本操作
style,可以修改该元素CSSStyleDeclaration集合中 CSS 属性的值,相当于行内样式(元素的style属性)
CSS 解析完,节点会调用 CSSStyleSelector 的 styleForElement 来给节点创建 RenderStyle 实例。 RenderObject 需要 RenderStyle 的排版信息。 CSSSstyleSelector 会从 CSSRuleList 里将匹配的样式属性取出来进行规则匹配。相关类图如下:
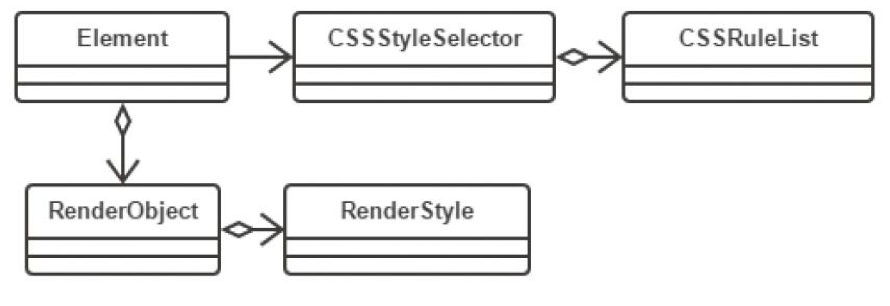
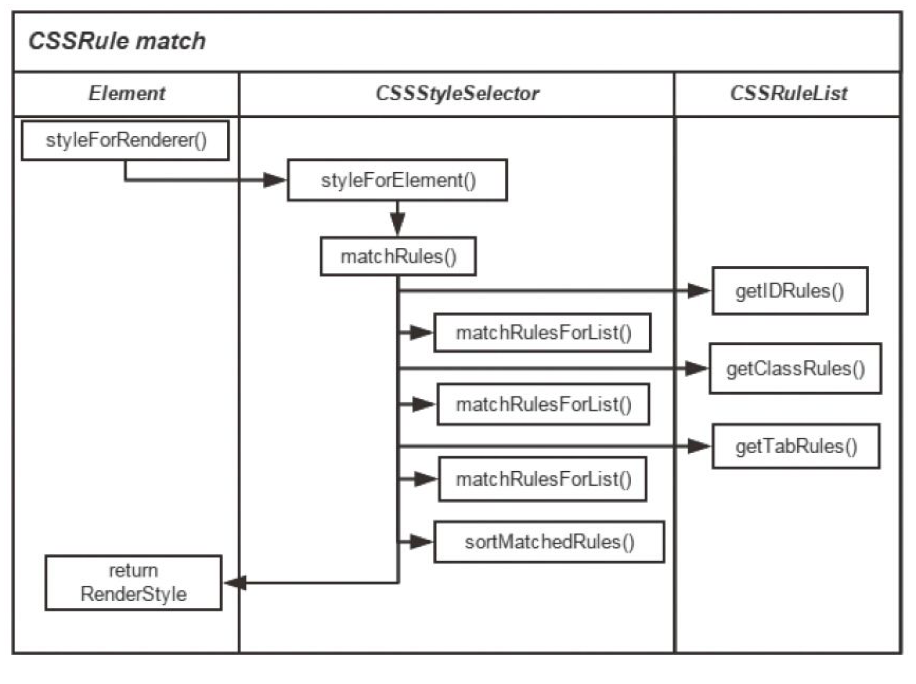
CSS 规则匹配的流程如下图所示:
渲染树的构建
在构建 DOM 树的同时,渲染引擎还构建了渲染树(Render Tree)。 CSSOM 和 DOM 树组合成一棵渲染树。然后用来计算每个可见元素的布局,并作为渲染过程的输入,将像素渲染到屏幕。渲染树只包含渲染页面所需的节点。
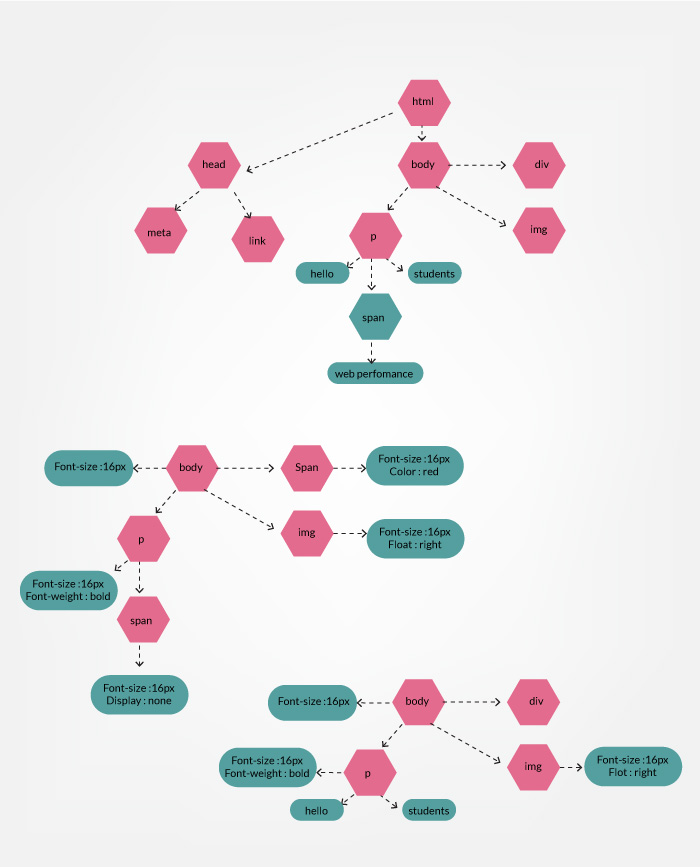
为了构建渲染树,浏览器大致做了以下工作:
- 从 DOM 树的根节点开始,遍历每个可见节点:有些节点是不可见的(比如
<script>、<link>等),由于它们没有反映在渲染的输出中,所以被省略了。有些节点是通过 CSS 隐藏,也从渲染树中省略了(比如设置了display: none的 DOM 节点) - 对于每个可见节点,找到适当的匹配的 CSSOM 规则并应用它们
- 发出带有内容和其计算样式的可见节点
浏览器渲染引擎会把渲染树和DOM树节点做映射(并不是一一对应的),也就是说,有些渲染对象(Render Object)有对应的 DOM节点(DOM Node),但是不在树的相同位置(比如,设置了绝对定位的元素),他们会放在树的其他地方。
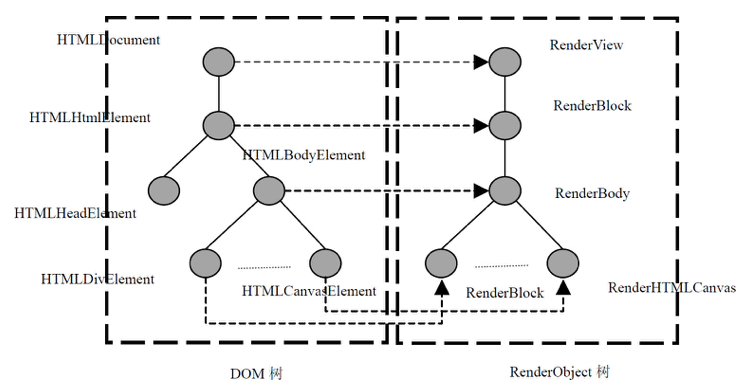
图:渲染树和DOM对做对应
在创建渲染树流程中,遇到 <html> 和 <body> 标记就会构建渲染树根节点,作为最上层的块(Block),包含了所有的块(Block),他的尺寸就是窗口大小(Viewport):
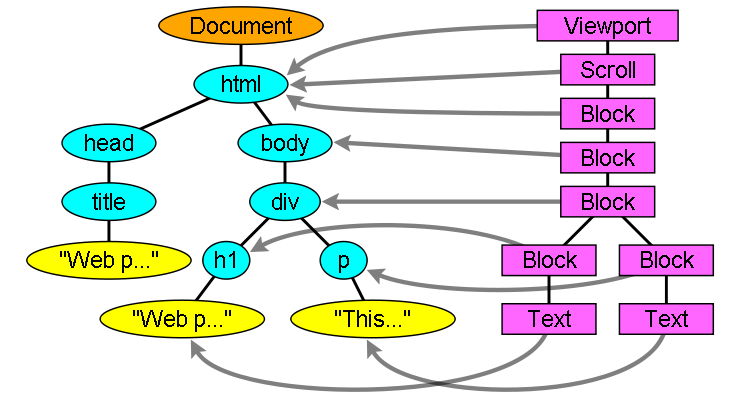
通过添加和删除元素,改变属性、为或通过动画来改变 DOM,都会导致浏览器重新计算元素样式,并且在很多情况下,对页面或其部分进行重排。这个过程也被称为 样式计算。样式计算我们将单独拿出来介绍。
布局过程
到渲染过程为止,我们得到了所有应该可见的节点和这些节点的样式属性。唯一缺少的属性是元素在设备视口(Viewport)中的位置和大小。这些是在布局过程中计算的。它也被称为 回流(重排)过程 。
有关于页面重排和重绘方面,更详细的内容可以阅读《理解 Web 的重排和重绘》。
布局是一个递归过程。它从根渲染器(<html> 元素)开始,通过框架层次结构中的一些或所有渲染器继续进行,这些渲染器需要计算几何信息。
在浏览器中, Dirty Bit System 被用来避免在发生小的变化时计算整个布局。当一个新的渲染器被添加或现有渲染器被更改时,它就会将自己及其子代标记为“脏位”(Dirty)。如果渲染器及其子代是脏的,就会使用“Dirty”标记。当渲染器没有被改变,但一个或多个子代被改变或添加时,“子代是脏的”标记就被设置。
全局布局过程(Global Layout Process)是指由于全局样式的变化而整个渲染树上触发的过程。例如,窗口大小的变化、全局样式的变化。全局布局通常是同步进行的。
递增式布局过程(Incremetal Layout Process)发生在以下情况:由于某个特定的渲染器或其子代的样式变化,或者增加了 DOM 节点,而在脏渲染器上触发该过程。递增式布局通常是以异步方式进行的,除非在某些特殊情况下,比如脚本请求样式值时。
绘制过程
绘制是将渲染树中的每个节点转换为屏幕上的实际像素的过程。它也被称为 “光栅化(Rasterizing)”。当布局完成后,浏览器发出 paint 事件,利用浏览器的基础设备组件在屏幕上实际绘制内容。
与布局过程类似,绘制过程也可以是全局或增量的。在全局绘制过程中,整个树被绘制。在增量绘制过程中,一些渲染器和它们的子节点被绘制。被修改的渲染器会使其在屏幕上的矩形失效,从而导致操作系统将该矩形视为“脏区域”(Dirty Region),并生成“涂抹(Paint)”事件。在 Chrome 中,这个过程很复杂,因为渲染器是在独立的进程中,而不是在主进程中。 Chrome 在一定程度上模拟了操作系统的行为。渲染器会监听这些事件,并将消息委托给渲染根节点(Render Root)。渲染树会被遍历,直到到达相关的渲染器。如果需要的话,它将重新绘制自己和它的子代。
绘制过程的顺序是由 CSS 规范定义的,是按照元素在层叠上下文中的层叠顺序进行的。这个顺序会影响绘制,因为层叠是从后往前画的。渲染器的层叠顺序是:背景色、背景图片、边框、子元素、轮廓。
浏览器试图对变化做出最小可能的反应。如果元素的颜色发生了变化,浏览器只会重新绘制该元素。如果元素的位置发生变化,浏览器将对该元素、子元素以及可能的同级元素进行重排和重绘。如果添加了 DOM 节点,浏览器将对该节点进行布局和绘制。如果发生了重大变化,比如根元素的字体大小变化,那么所有的布快叫 缓存都会失效,整个树的重排和重绘会进行。
渲染引擎的基本过程
渲染引擎的主要工作就是把页面的 HTML 和 CSS 文件中转化为屏幕上显示的像素点。
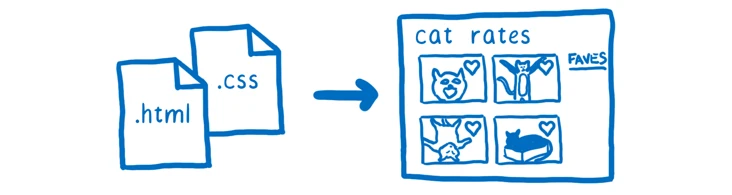
想要把文件转化为屏幕上像素点,目前主流浏览器的渲染引擎基本上都会做以下相同的事情。
Step01: 把 HTML 文件解析成浏览器能理解的对象,包括 DOM。从这个角度来说, DOM 掌握了整个页面结构。它知道每个元素之间的相互关系:父子、兄弟 或 后代,相当于一个家族的族谱:
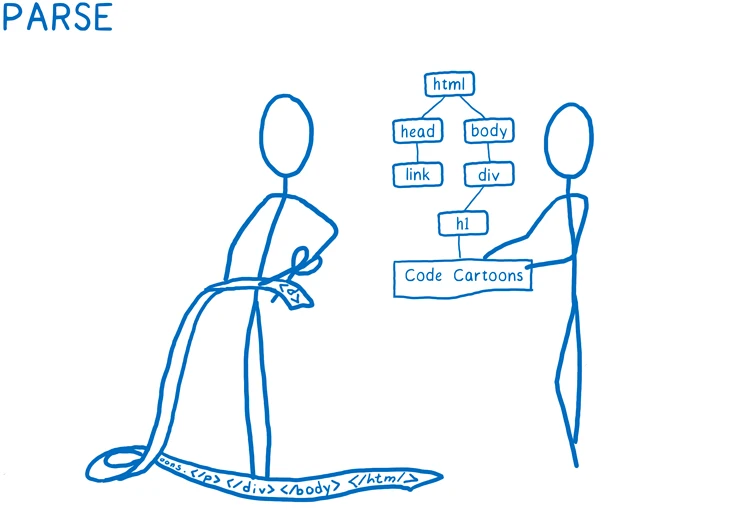
图:从 HTML 到 DOM 树过程(HTML经过 HTML Parser 处理之后得到一棵 DOM 树)
Step02:弄清楚每个元素应该长什么样子(UI 效果)。对于每个 DOM 节点 (DOM Node),CSS 引擎会弄清楚应该在 DOM 节点上采用哪些 CSS 规则。然后,会计算出每个 CSS 属性的值。
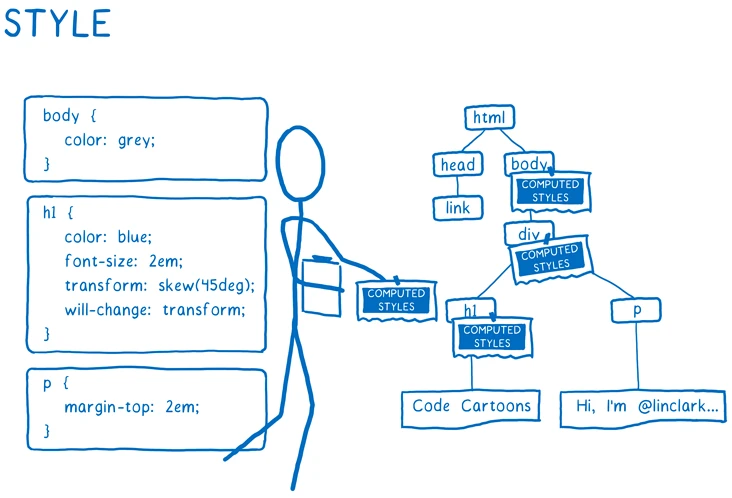
图:从 CSS 到 CSSOM 过程(CSS 经过 CSS Parser 之后得到 CSSOM 树)
Step03:计算出每个DOM 节点的尺寸和位在屏幕上的位置。为每个要在屏幕上显示的内容创建盒模型。这些盒模型不仅仅用来表示 DOM 节点,也用来表示 DOM 节点的内部内容,比如元素的文本内容(文本节点):
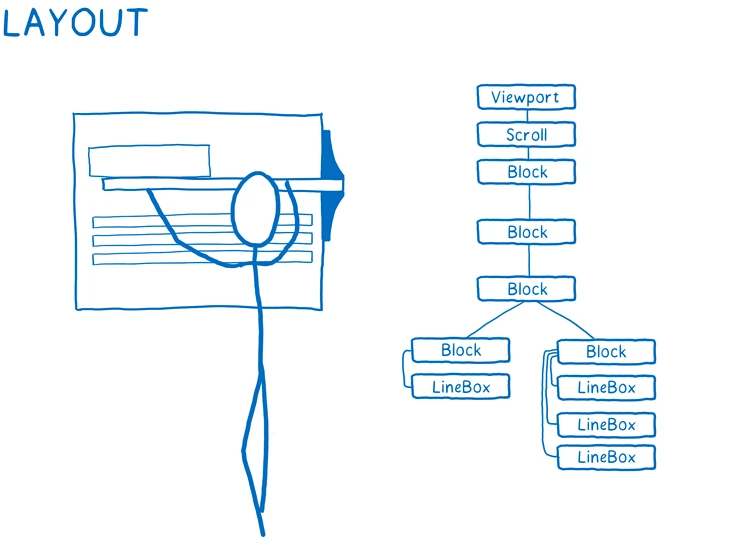
图:DOM 和 CSSOM 的结合,构建渲染树(Render Tree)
Step04:绘制不同的盒模型。这可以发生在多个图层上。它就像是以前使用半透明纸
剩余80%内容付费后可查看
如需转载,烦请注明出处:https://www.w3cplus.com/performance/write-efficient-css-selectors.html
如果文章中有不对之处,烦请各位大神拍正。如果你觉得这篇文章对你有所帮助,打个赏,让我有更大的动力去创作。(^_^)。看完了?还不过瘾?点击向作者提问!
赏杯咖啡,鼓励他创作更多优质内容!


